
Automating stock investments with computers has probably been one of this century’s most compelling tasks, and several techniques and approaches have emerged in the years. During the last semester, I had the pleasure of taking the Combinatorial Decision Making and Optimisation exam at the University of Bologna, which required a final project that exploited the techniques seen in the course.
Having always been fascinated by finance, I imagined this might be a good occasion to actually learn something about both worlds: numerical optimization and the stock market.
Stock portfolio selection is the task concerned with the creation of portfolios of stock symbols, trying to maximize the return and minimize the risk we’re expecting. The advantage of investing in several stocks rather than just one is pretty obvious: it is way less risky than just investing in a single firm, which might be super lucky.. or super bad.
We still want some kind of non-determinism in how the agent chooses a portfolio: this requires some iterative method in our numerical optimization!
Nelder-Mead method
The Nelder-Mead method is definitely great for this task: it is a simplex-based method that is able to find the minimum or maximum of an objective function in a multi-dimensional space.
Okay but, what’s a simplex?
Imagine we were working with a 2-variable function (therefore, in a 2D space) which we want to minimize. Let’s say, for instance, that this function is the Rosenbrock banana function, 

Now, what the algorithm does is the following: it generates a random simplex, i.e. a polytope having 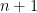
How is this polytope moved?
Nelder and Mead proposed 4 different types of movement for this polytope:
- Reflection: the polytope is moved in a direction that’s away from the sub-optimal region it sits in. To do so, we take the worst point, and re-compute its position as
, where
is the centroid of the points of the simplex (without this one) and
is the original position. Basically, we’re taking the line passing between the centroid and the worst point, and we’re moving the worst point away from the centroid, along this line;
- Expansion: if we are truly lucky, and the reflected point is so good that it beat the best point in our simplex, we’ll want to exploit our luck a little more, and try moving it in the same direction for some more:
;
- Contraction: maybe we weren’t so lucky after all, and reflection worsened our values. Probably this means that the direction we were moving (basically, enlarging the simplex) wasn’t that good. We might want to try and do the inverse, then! This is exactly what it’s done: we’re contracting the simplex towards the centroid
- Shrinkage: if we really are not lucky, the preceding steps have failed. We have one last chance: recomputing every point in the simplex except for the best one, moving the whole simplex towards this one. Every point will therefore be computed as
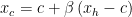
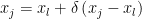
The algorithm terminates after a given amount of steps, or when the polytope is really small: this condition is encoded with a constraint on the standard deviation of the points.
Implementation
How is this done in Python? You can check the code here. Basically, we instantiate a NelderMead object, specifying the hyperparameters we need: the reflection, expansion, contraction, and shrinkage parameters, and some other utilities for the stock task.
Then, the iterate method manages the actual optimization: it first tries to compute the reflection, then the expansion, the contraction, and the shrinkage. You can try the pure optimization method by starting the Python script nelder_mead.py.
How do I make money out of this?🤑
Now, we only need some stock historical data, compute the expected returns and the risk, and see what happens. In mathematical terms, our objective function is the sum of the 
The data
One could use datasets like this one, but using old data would defeat our purpose. We want our data to be the freshest possible. This is where AlphaVantage enters the scene: a simple API that retrieves stock data for the last years, given its symbol. As easy as it sounds. Furthermore, the guys at AlphaVantage provide a cool Python wrapper that makes everything idiot-proof.
We just need an API key, and we can just query the engine like this:
for symbol in self.symbols:
self.stocks_data[symbol] = ts.get_daily(
symbol=symbol, outputsize='full')
Then, we could consider the expected return as the return for the same time interval, in the past. But that would be way too easy. A good idea might be trying to optimize the time-series with some specialized tool: Darts. Thanks to Darts, we can try to infer the return we’ll have in the future using a Temporal Convolutional Network.
This is rather easy:
def predict_stock_return(self, data, days_from_now):
"""Predicts the return and risk over the investment horizon
Args:
close_prices (Pandas DataFrame): Time series containing the closing prices
days_from_now (int): Investment horizon
Returns:
tuple: Return forecast, risk forecast
"""
series = DartsTS.from_dataframe(
data.head(1000), 'index', "4. close", freq="B")
model_tcn = TCNModel(
input_chunk_length=50,
output_chunk_length=30,
n_epochs=400,
dropout=0.1,
dilation_base=2,
weight_norm=True,
kernel_size=5,
num_filters=3,
random_state=0
)
model_tcn.fit(fill_missing_values(series))
prediction_aarima = model_tcn.predict(days_from_now)
risk = abs(
np.std(prediction_aarima.values()))
return prediction_aarima.values()[-1][0], risk
Now, we can just divide these expected returns by their risk (which we’ll simplify as the standard deviation over the time interval), and obtain a new ror (i.e., Return over Risk) column in our dataset.
Finally, we instantiate the NelderMead object we introduced before, and let it do its thing.
def optimize(self, reflection_parameter=1, expansion_parameter=2, contraction_parameter=0.1, shrinkage_parameter=0.5, max_iterations=15, shift_coefficient=0.05):
print("Starting optimization...")
self.nm = NelderMead(len(self.symbols), self.objective_function, 1, reflection_parameter, expansion_parameter,
contraction_parameter, shrinkage_parameter, max_iterations, shift_coefficient)
self.nm.initialize_simplex()
results = self.nm.fit(0.0001) # Stop when std_dev is 0.0001
print("Optimization completed!")
money = 0
for i in range(len(self.symbols)):
print(
f"The stock {self.symbols[i]} should be {round(results[i]*100,2)}% of your portfolio")
money += ((1000*results[i])/(self.stocks_analysis["OpenPrice"].iloc[i])
* self.stocks_analysis["Prediction"].iloc[i])
print(
f"The predicted return for a 1000$ investment is {round(money, 2)}$")
This is it! All the code is available on my Github, here. That’s the final result:

Thanks for reading this article, have some wonderful coding ✨